
Functional Delay Networks Series of Swiss public transport in August 2025#
In this demo we process pre-aggregated delay time series to extract a functional delay network using the delaynet package. The event-level extraction and aggregation (from SBB realised timetable
data to 15‑minute station bins) was performed externally and is not shipped with this demo; we therefore start from monthly CSVs that already contain, for each station_id × time_bin, the summed
arrival delay delay_sec_sum. If you wish to reproduce this on your own data, prepare an equivalent long-format table as described in Data preparation and then follow the same steps below.
Reminder: We focus on the subset of SBB-operated long‑distance services with
long_distance_prefixes = ['IC', 'IR', 'EC', 'ICE', 'TGV'], drawing from the open historic dataset.
import delaynet as dn
import geopandas as gpd
import contextily as cx
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
from matplotlib.colors import ListedColormap
import numpy as np
import networkx as nx
# Load station metadata (long-distance stations) prepared externally
stops_long_distance_gdf = gpd.read_file("./stops_long_distance_gdf_07-2025.geojson")
stops_long_distance_gdf.explore(
column="log_count",
markersize=1,
tiles="CartoDB.Positron",
marker_kwds={"radius": 7},
)
Delay data has been preprocessed externally into 15-minute aggregates per station and time bin, stored as
delay_sec_sumvalues. See the preparation overview in Data preparation for the expected input format and cleaning considerations.Station metadata for long-distance services is provided via
stops_long_distance_gdf_07-2025.geojson(GeoJSON). We focus on SBB-operated long-distance prefixes. For a refresher on assembling time series matrices for network work, see Network reconstruction and Connectivity overview.
First, we are interested in the 15 min binned data.
| station_id | time_bin | delay_sec_sum | |
|---|---|---|---|
| 0 | 8500010 | 2025-08-01 08:00:00+00:00 | -50 |
| 1 | 8500010 | 2025-08-01 08:30:00+00:00 | -70 |
| 2 | 8500010 | 2025-08-01 08:45:00+00:00 | -184 |
| 3 | 8500010 | 2025-08-01 09:00:00+00:00 | 644 |
| 4 | 8500010 | 2025-08-01 09:15:00+00:00 | -143 |
This array includes for each station and time bin the sum of the delays in delay_sec_sum. The head of the table shows for 8500010 (Basel SBB) for most columns a negative value, which means most
trains must be colloquially “on time”, but really arrive a bit before the scheduled time, which is the desired case. One of the shown bins is positive and points to delayed trains.
We must emphasise that the observed sum is only a macroscopic measure and not per-train, as we cannot say if the delay comes by one really delayed train, or is a sum of many small late arrivals. For
the analysis, this is not a problem.
The stations of interest are the stations in stops_long_distance_gdf["station_id"]. To make the analysis faster, we might only take a subset of them. As the most large stations are the first ones,
we can take the first \(n=50\) train stations.
stops_long_distance_gdf[:6]
| station_id | count | designationofficial | abbreviation | cantonabbreviation | height | log_count | geometry | |
|---|---|---|---|---|---|---|---|---|
| 0 | 8503000 | 17906 | Zürich HB | ZUE | ZH | 407.70 | 9.792891 | POINT (2683189.561 1248065.978) |
| 1 | 8500010 | 9566 | Basel SBB | BS | BS | 276.75 | 9.165970 | POINT (2611362.891 1266309.826) |
| 2 | 8501120 | 9354 | Lausanne | LS | VD | 447.09 | 9.143559 | POINT (2537874.991 1152042.412) |
| 3 | 8500218 | 7950 | Olten | OL | SO | 396.00 | 8.980927 | POINT (2635441.909 1244670.532) |
| 4 | 8501008 | 7023 | Genève | GE | GE | 392.01 | 8.856946 | POINT (2499968.949 1118468.129) |
| 5 | 8507000 | 6496 | Bern | BN | BE | 540.20 | 8.778942 | POINT (2600037.945 1199749.812) |
n = 50
arrival_delay_15mins_df = arrival_delay_15mins_df[
arrival_delay_15mins_df["station_id"].isin(
stops_long_distance_gdf["station_id"][:n]
)
]
The data is a table of station_id, time_bin, and delay_sec_sum. From this, we want to make a matrix of station_id and time_bin and the delay_sec_sum as the values. A matrix of shape (
n_stations, n_time_bins) where the stations are sorted by stops_long_distance_gdf["station_id"][:n] and the time bins are sorted by, well, time. As 0-values are just left out in the delay DataFrame,
we need to fill them with zeros.
print(list(stops_long_distance_gdf["station_id"][:n]))
[8503000, 8500010, 8501120, 8500218, 8501008, 8507000, 8501026, 8503016, 8506000, 8501118, 8505000, 8504100, 8506302, 8501037, 8501030, 8501609, 8500023, 8502113, 8502204, 8503504, 8500309, 8503006, 8501605, 8504300, 8509411, 8501300, 8501506, 8501400, 8504200, 8504221, 8501200, 8501500, 8506206, 8506208, 8506210, 8506209, 8500026, 8501509, 8504023, 8504014, 8500305, 8500301, 8507483, 8507100, 8502001, 8502007, 8500207, 8509002, 8509000, 8506311]
# -> matrix format (n_stations, n_time_bins)
arrival_delay_15mins_matrix = arrival_delay_15mins_df.pivot_table(
index="station_id", columns="time_bin", values="delay_sec_sum", fill_value=0
)
# Reorder according to stops_long_distance_gdf["station_id"][:n]
arrival_delay_15mins_matrix = arrival_delay_15mins_matrix.reindex(
stops_long_distance_gdf["station_id"][:n]
)
arrival_delay_15mins_matrix.shape
(50, 2709)
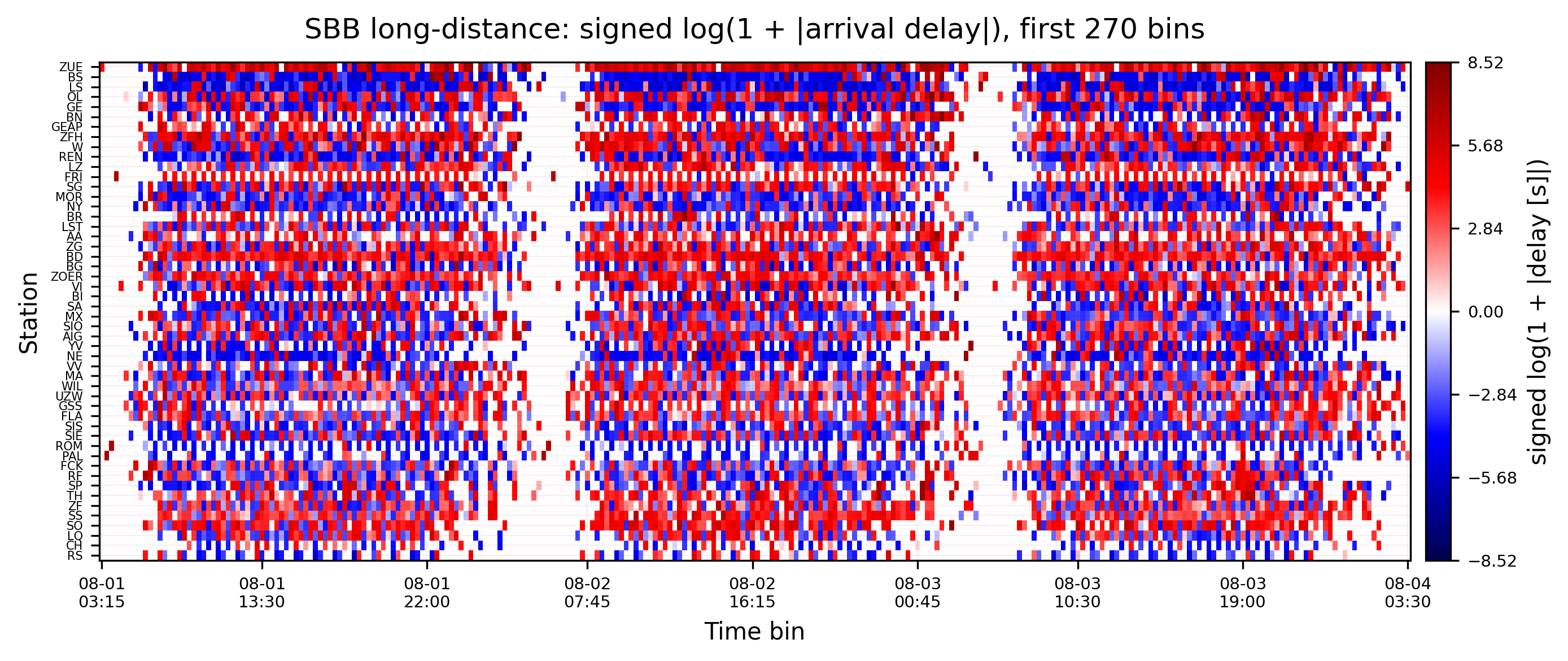
For these three days, you see that each station has their own arrival delay pattern that repeats daily. At the same time stations are not comparable in intensity and periodic pattern. While some stations regulariliy have positive arrival delay sums, others are negative, some alternating. To combat this and make them stationary, so connectivity measures can grasp them, detrending is essential. See the Detrending overview and the specific Z-Score detrending we will apply below.
Functional delay network#
1. Detrending#
The data has a daily and possibly weekly seasonality. We calculate the Z-Score with a 24h periodicity. With the 15 minutes data, this means a \(\frac{1\,\rm{day}}{15\,\rm{min}}=24\times 60\,\rm{min}/15\,\rm{min} = 96\) periodicity. For details and alternatives, see Detrending.
arrival_delay_15mins_matrix_detrended = dn.detrend(
arrival_delay_15mins_matrix.to_numpy(), method="z-score", periodicity=96, axis=1
)
arrival_delay_15mins_matrix_detrended.shape
(50, 2709)
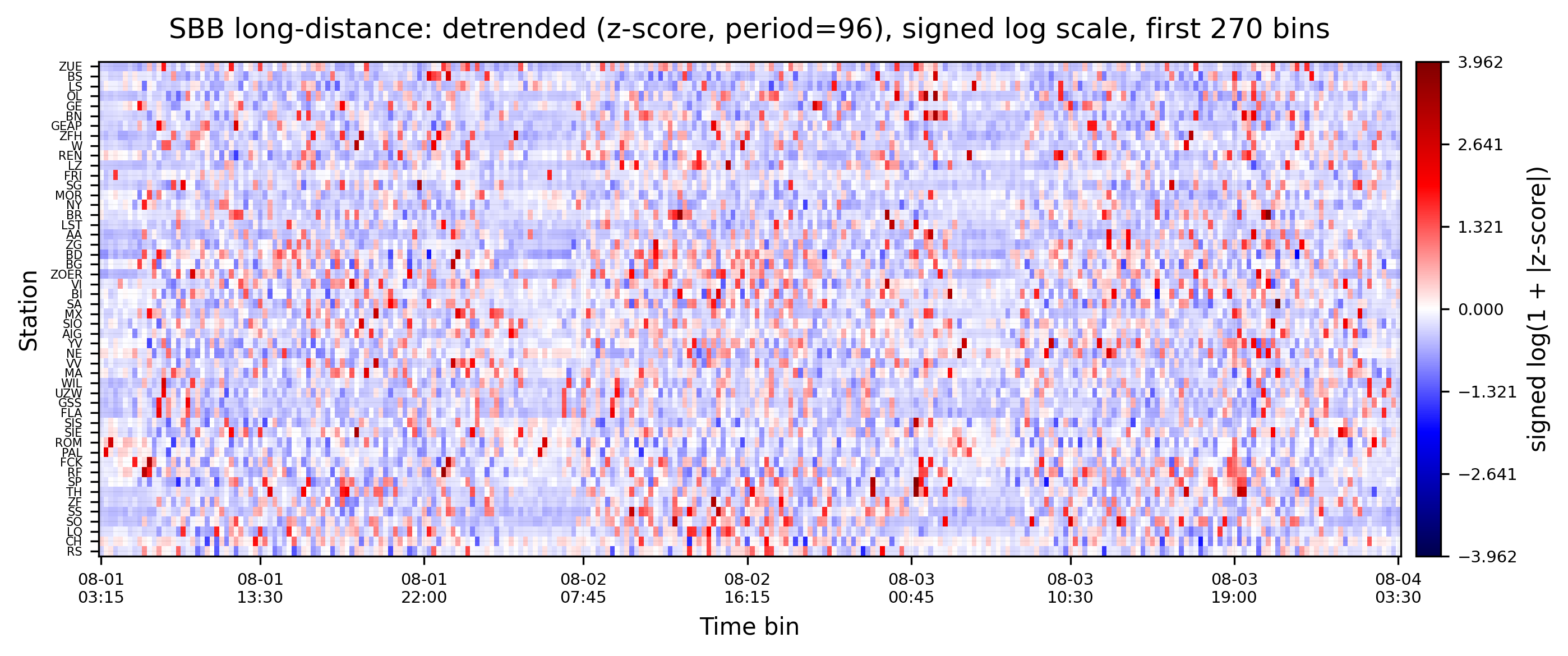
You can clearly see that the data is detrended and stationary when compared to the plot before. Now, each station’s signal is centered around zero, and the variance is reduced. Patterns with periodicity of 24h are also reduced.
2. Functional Delay Network Reconstruction#
weights, lags = dn.reconstruct_network(
arrival_delay_15mins_matrix_detrended.T,
connectivity_measure="gc", # Granger Causality
lag_steps=16, # 4h max delay tested
# workers=10,
)
Sequential: [##############################] 2450/2450 (100.0%) Time: 1.6m
We reconstruct a directed functional delay network using Granger causality over up to 4 hours of lags.
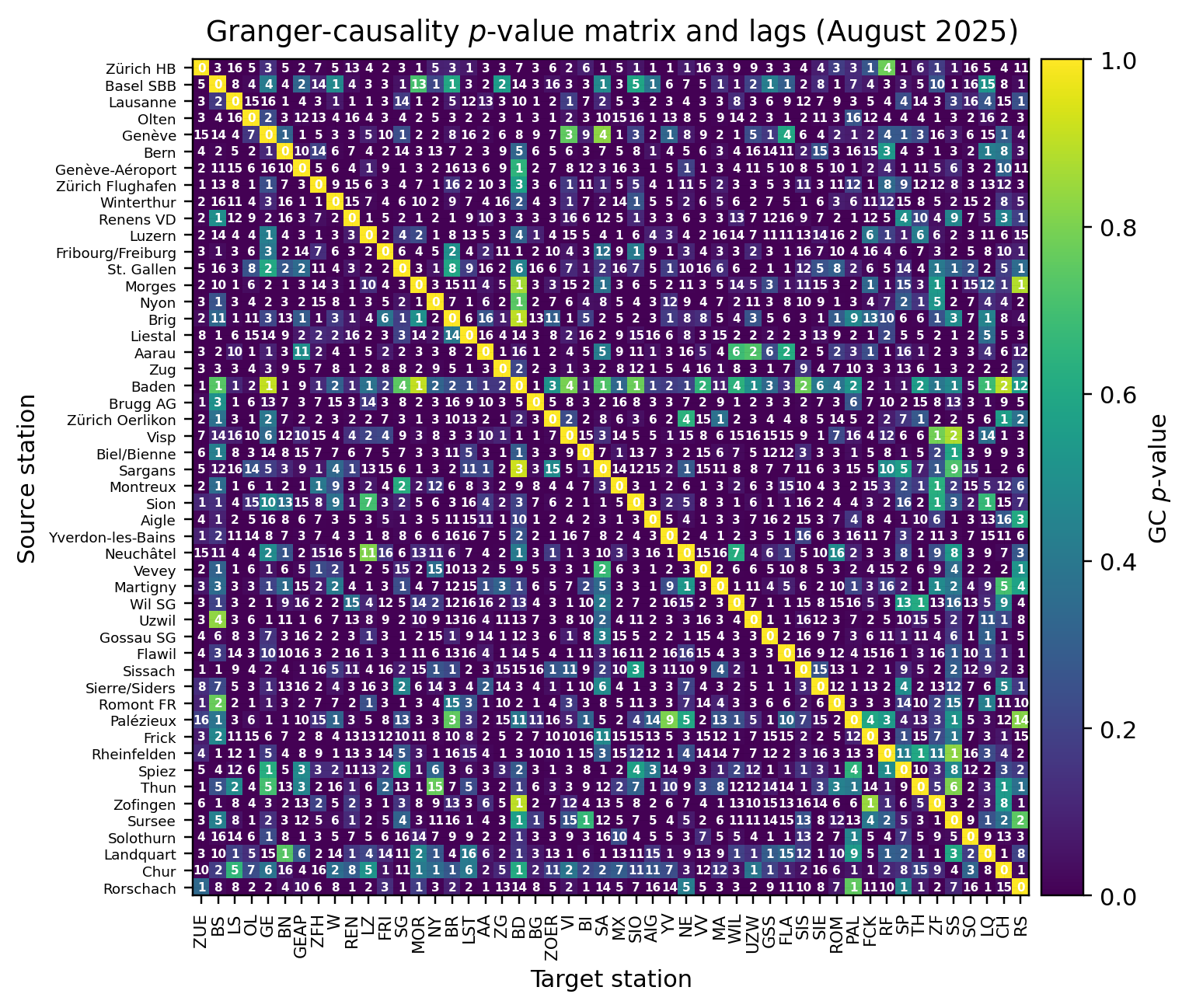
We now turn the dense \(p\)-value matrix into a sparse, directed adjacency by keeping only statistically significant links. We use α = 0.01 with Benjamini–Hochberg FDR control to account for multiple testing across all pairs. The result is a boolean mask where True = link kept. See Connectivity and Network Reconstruction for background on \(p\)-values, multiple testing, and pruning choices.
significant_connections = dn.network_analysis.statistical_pruning(
weights, alpha=0.01, correction="fdr_bh"
)

Reading the pruned matrix: black cells indicate kept (statistically significant) directed links i→j; white cells indicate pruned pairs. Rows are sources, columns are targets. Axis labels use station abbreviations (x) and official names (y) for orientation.
We convert the pruned adjacency into a directed NetworkX graph. Each row/column index corresponds to the station ordering used above; edges point from source (row) to target (column). This preserves the directionality of delay propagation. For geographic context, see the map view below.
G = nx.from_numpy_array(significant_connections, create_using=nx.DiGraph)
Now let’s plot this on the map. To place the abstract graph in geographic context, we place nodes at their station coordinates and overlay two basemaps (CartoDB and OpenRailwayMap).
node_sizes = (
100
+ stops_long_distance_gdf["count"] / stops_long_distance_gdf["count"].max() * 200
)
n = 50
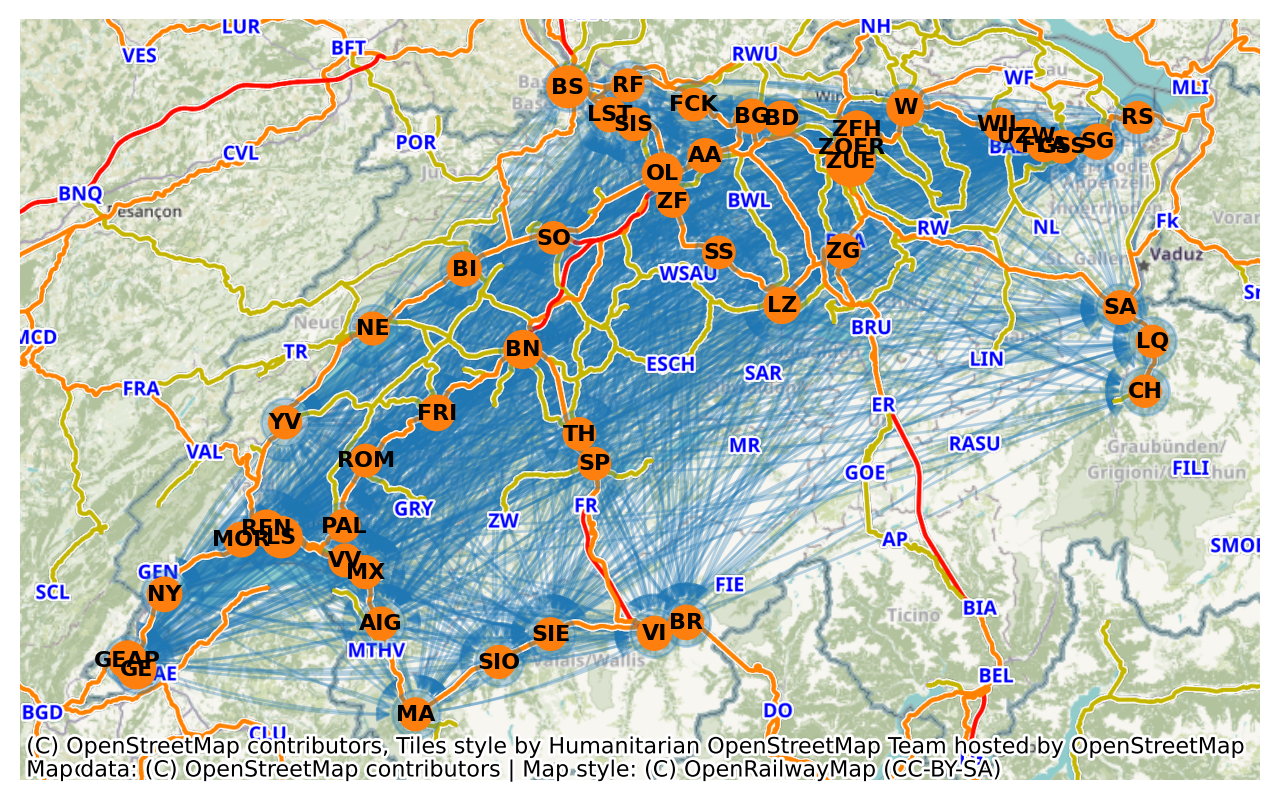
3. Functional Delay Network Analysis#
Now infomeasure includes a number of network analysis functions which can easily be called on the pruned network, like so:
# Convert boolean mask to binary adjacency matrix
binary_adjacency = significant_connections.astype(int)
# Calculate link density
density = dn.network_analysis.link_density(binary_adjacency)
print(f"Link density: {density:.4f}")
# Find isolated nodes
isolated_in = dn.network_analysis.isolated_nodes_inbound(binary_adjacency)
isolated_out = dn.network_analysis.isolated_nodes_outbound(binary_adjacency)
print(f"Nodes with no incoming connections: {isolated_in}")
print(f"Nodes with no outgoing connections: {isolated_out}")
# Calculate betweenness centrality
betweenness = dn.network_analysis.betweenness_centrality(
binary_adjacency, normalise=True
)
print(f"Betweenness centrality: {betweenness}")
# Calculate eigenvector centrality
eigenvector = dn.network_analysis.eigenvector_centrality(
binary_adjacency, normalise=True
)
print(f"Eigenvector centrality: {eigenvector}")
# Calculate global efficiency
efficiency = dn.network_analysis.global_efficiency(binary_adjacency, normalise=True)
print(f"Global efficiency: {efficiency:.4f}")
# Calculate transitivity
trans = dn.network_analysis.transitivity(binary_adjacency, normalise=True)
print(f"Transitivity: {trans:.4f}")
# Calculate reciprocity (only for directed networks)
recip = dn.network_analysis.reciprocity(binary_adjacency, normalise=True)
print(f"Reciprocity: {recip:.4f}")
Link density: 0.5143
Nodes with no incoming connections: 0
Nodes with no outgoing connections: 0
Betweenness centrality: [ 3.18883728 -4.94291384 3.6862082 9.12121788 -3.64456172 2.84948463
3.61455764 -0.1327453 -1.39159743 -2.94629722 0.29048022 1.27308985
-2.46824501 -0.65476335 0.19678942 -3.49555222 2.25815556 0.51800054
2.82700469 -4.71042075 13.60485487 -1.52527521 0.10947252 4.98021065
-2.75750965 -0.46103533 -1.64934587 2.55494635 1.14541104 -3.00548935
7.49215706 -3.11309281 0.05501394 1.34195019 2.21974008 0.72419998
-1.74627825 1.24887435 0.18791854 -3.57226878 -3.06466005 -2.85093597
-4.33894866 -2.7434172 -2.04131327 -1.57614079 0.72949755 -0.81324334
-4.24756831 -2.33767465]
Eigenvector centrality: [ 0.93210474 -4.93601417 3.17023149 3.2356579 -5.11804375 2.61116891
-0.35700017 -1.09730729 -0.83985993 0.4204134 -0.85988043 3.10782775
-3.37357986 0.32508922 0.45722487 0.16034351 0.51559885 -2.09989085
2.50992298 -3.13905511 4.28009036 1.50462083 -1.05109426 2.53497245
-3.60266514 1.13251607 0.04550356 2.60415363 1.15945607 -1.80847609
3.15115412 -0.82143743 -0.53319375 2.18267649 2.59669412 1.18635315
-2.02632476 1.27530116 0.61614841 -2.82911415 -1.64697861 -1.88761402
-5.34713255 -2.57310339 -3.64543826 -5.84920891 1.53720435 -2.9950427
-2.50410155 -3.50723491]
Global efficiency: -919101964768.5000
Transitivity: -2.2526
Reciprocity: 9.9891
Some of these metrics are discussed within the Network reconstruction guide (see the analysis and examples at the end of that page); for context on pruning and interpretation within the pipeline, see also Connectivity.
Before plotting centralities on the map, we encode two ideas: node size \(\propto\) betweenness (bottleneck potential) and node colour \(\propto\) eigenvector centrality (being connected to other central nodes). Arrows remain directed; together these cues help spot hubs, bridges and periphery. Basemap layers provide geographic context (roads/rails) but the topology is purely functional.
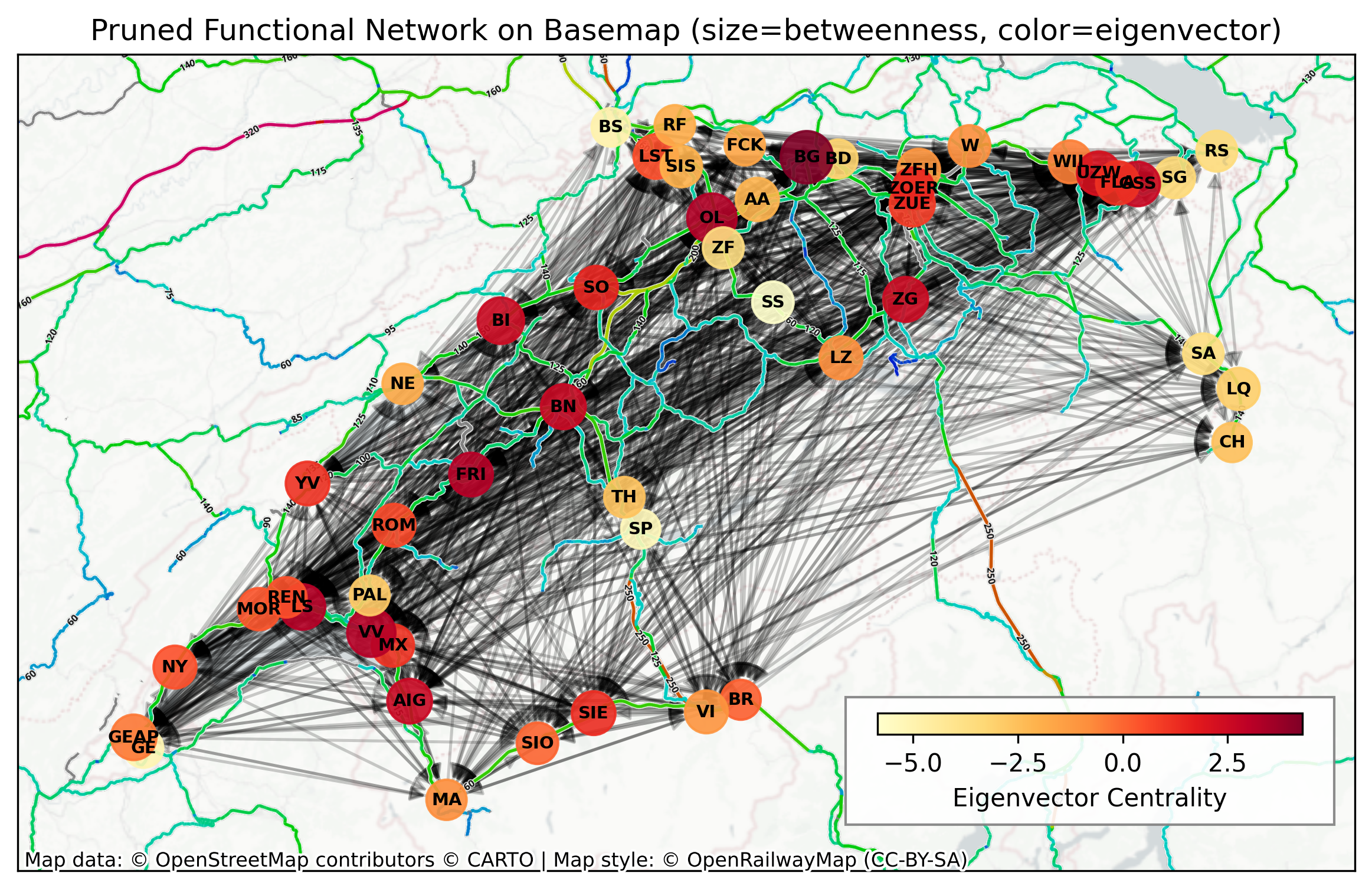
Interpreting sizes and colours: larger nodes often act as mediators of many shortest paths (high betweenness), while dark red colours (higher eigenvector) indicate influence via other influential neighbours. Comparing visually with the earlier binary map—centrality encodings can reveal role asymmetries not obvious from link density alone.
Stations with the highest betweenness centrality:
1. Brugg AG 13.605
2. Olten 9.121
3. Vevey 7.492
4. Biel/Bienne 4.980
5. Lausanne 3.686
6. Genève-Aéroport 3.615
7. Zürich HB 3.189
8. Bern 2.849
9. Zug 2.827
10. Aigle 2.555
Stations with the highest eigenvector centrality:
1. Brugg AG 4.280
2. Olten 3.236
3. Lausanne 3.170
4. Vevey 3.151
5. Fribourg/Freiburg 3.108
6. Bern 2.611
7. Aigle 2.604
8. Gossau SG 2.597
9. Biel/Bienne 2.535
10. Zug 2.510
Community Detection#
We also inspect meso-scale structure via Louvain communities. Here we convert the directed graph to undirected just for community detection and weight undirected edges by 1 (unidirectional) or 2 ( bidirectional) occurrences. Community colours nodes while sizes remain tied to betweenness for continuity with the previous plot. Use this to spot regional clusters or tightly interacting station groups.
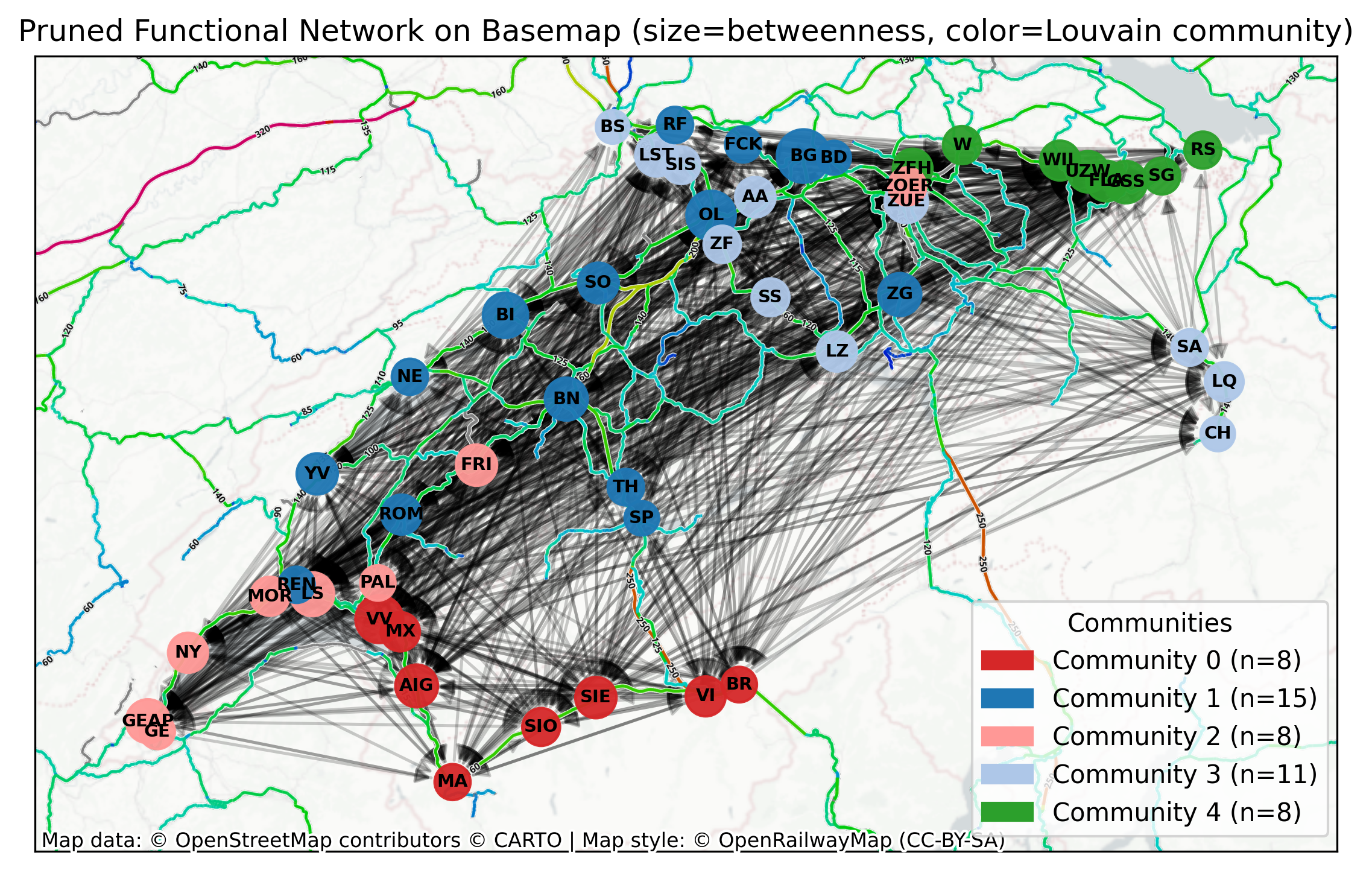
How to read the map layers: edge colours reflect the lag legend (when enabled) and only significant links are plotted. Remember \(p\)-values express statistical significance, not effect size; pairwise tests can miss indirect paths.
A brief summary: This demo shows an end-to-end workflow on real-world SBB long-distance data for a single month. We assemble station-wise delay time series, apply Z-Score detrending with daily periodicity, reconstruct a directed functional network via Granger Causality, statistically prune connections, and analyse structure with centralities and communities. For the conceptual background, more options, interpretation and multiple testing, see Detrending, Connectivity, and Network Reconstruction.